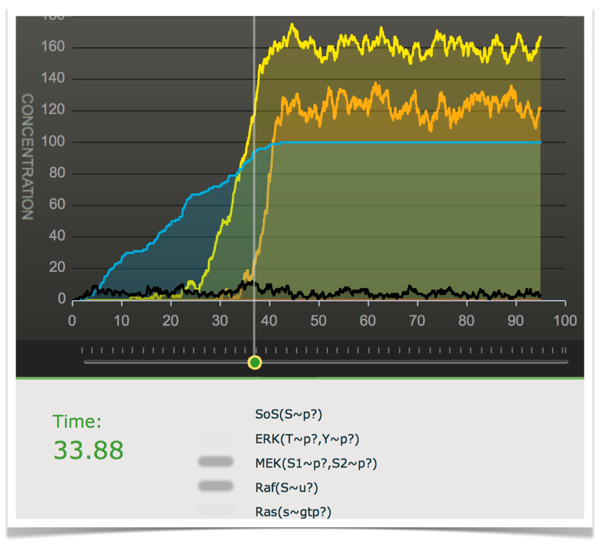
My first post on the Ronin Institute blog:
Open science has well and truly arrived. Preprints. Research Parasites. Scientific Reproducibility. Citizen science. Mozilla, the producer of the Firefox browser, has started an Open Science initiative. Open science really hit the mainstream in 2016. So what is open science? Depending on who you ask, it simply means more timely and regular releases of data sets, and publication in open-access journals. Others imagine a more radical transformation of science and scholarship and are advocating “open-notebook” science with a continuous public record of scientific work and concomitant release of open data. In this more expansive vision: science will be ultimately transformed from a series of static snapshots represented by papers and grants into a more supple and real-time practice where the production of science involves both professionals and citizen scientists blending, and co-creating a publicly available shared knowledge. Michael Nielsen, author of the 2012 book Reinventing Discovery: The New Era of Networked Science describes open science, less as a set of specific practices, but ultimately as a process to amplify collective intelligence to solve scientific problems more easily:
To amplify collective intelligence, we should scale up collaborations, increasing the cognitive diversity and range of available expertise as much as possible. This broadens the range of problems that can be easy solved … Ideally, the collaboration will achieve designed serendipity, so that a problem that seems hard to the person posing it finds its way to a person with just the right microexpertise to easily solve it.