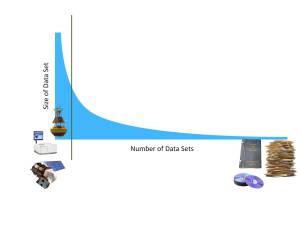
 Scientists are increasingly examining the most comprehensive catalogue of datasets for any particular question. Making sure you can find as much of the data relevant to a particular problem thus begins to loom as a large issue. Although institutional repositories (such as NCBI, Dryad, Figshare etc.) are great at storing the final published versions of the data sets, some early and smaller-scale research data can get lost in the “long-tail“. Anne Thessen has a great post over on her blog on the Data Detektiv, on how to locate and keep track of such “dark data”:
Scientists are increasingly examining the most comprehensive catalogue of datasets for any particular question. Making sure you can find as much of the data relevant to a particular problem thus begins to loom as a large issue. Although institutional repositories (such as NCBI, Dryad, Figshare etc.) are great at storing the final published versions of the data sets, some early and smaller-scale research data can get lost in the “long-tail“. Anne Thessen has a great post over on her blog on the Data Detektiv, on how to locate and keep track of such “dark data”:
Finding relevant data, especially if the needed data are dark, can be a difficult and lengthy task. … Was there a way to discover data based on events earlier in the research workflow? After some thought, I realized that databases and lists of awards made by funding agencies were an…
View original post 21 more words
